
SynthID-Text: A Scalable Watermarking Scheme for Identifying Large Language Model-Generated Text
This article introduces a novel text watermarking technique called SynthID-Text designed to address the challenge of identifying text generated by large language models (LLMs).
The article highlights the increasing realism and potential misuse of LLM-generated text, emphasizing the need for reliable identification methods. It argues that existing watermarking techniques have fallen short in terms of practicality, particularly regarding text quality, detectability, and computational efficiency.
SynthID-Text is presented as a solution that overcomes these limitations. It operates by subtly modifying the sampling procedure during text generation without impacting the LLM training process. The watermark itself is designed to be undetectable to human readers but easily identifiable by an algorithm, ensuring the text's usability and the watermark's effectiveness.
The article emphasizes SynthID-Text's scalability, achieved through integration with speculative sampling, a common technique for enhancing LLM efficiency. This integration ensures the watermarking process doesn't significantly impact the performance of large-scale LLM deployments.
Empirical evidence is presented to support SynthID-Text's effectiveness. Evaluations across various LLMs demonstrate its superior detectability compared to existing methods. Moreover, standard benchmarks and human evaluations confirm that SynthID-Text doesn't compromise the quality or capabilities of the LLMs it's applied to.
The article concludes by highlighting a live experiment involving nearly 20 million responses from the Gemini LLM, further validating SynthID-Text's practicality and lack of impact on text quality. The authors express hope that SynthID-Text will encourage responsible LLM use and further development in the field of text watermarking.
요약 맞춤 설정
AI로 다시 쓰기
인용 생성
소스 번역
다른 언어로
마인드맵 생성
소스 콘텐츠 기반
소스 방문
www.nature.com
Scalable watermarking for identifying large language model outputs - Nature
핵심 통찰 요약
by Sumanth Dath... 게시일 www.nature.com 10-23-2024
https://www.nature.com/articles/s41586-024-08025-4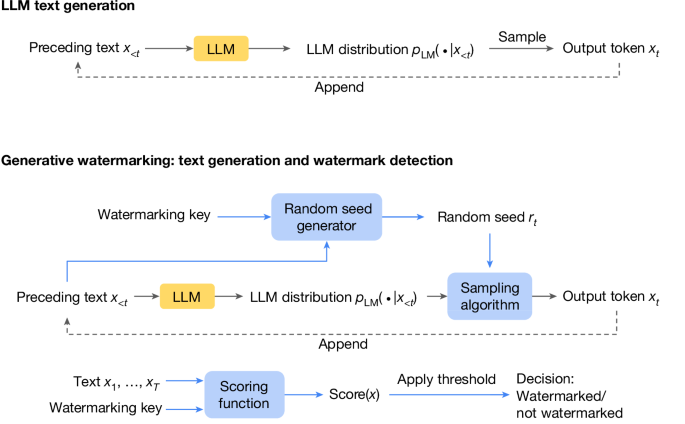
더 깊은 질문
What are the potential ethical implications of using watermarking technology to track and identify LLM-generated text, particularly in contexts where freedom of expression and anonymity are paramount?
Could adversaries develop techniques to circumvent or remove the SynthID-Text watermark while preserving the quality and coherence of the generated text?
How might the development of increasingly sophisticated text watermarking techniques like SynthID-Text influence the future of digital content creation and attribution in an era of rapidly advancing artificial intelligence?
© 2024 by Linnk AI