
Detecting Fabricated Outputs in Large Language Models Using Semantic Entropy
The content discusses the problem of hallucinations in large language models (LLMs) such as ChatGPT and Gemini. LLMs can sometimes generate false or unsubstantiated answers, which poses a significant challenge for their adoption in diverse fields, including legal, news, and medical domains.
The authors propose a new method to detect a subset of hallucinations, called "confabulations", which are arbitrary and incorrect generations. The key idea is to compute the uncertainty of the model's outputs at the level of meaning rather than specific sequences of words, using an entropy-based approach.
The proposed method has several advantages:
- It works across datasets and tasks without requiring a priori knowledge of the task or task-specific data.
- It can robustly generalize to new tasks not seen before.
- By detecting when a prompt is likely to produce a confabulation, the method helps users understand when they must take extra care with LLMs, enabling new possibilities for using these models despite their unreliability.
The authors highlight that encouraging truthfulness through supervision or reinforcement has only been partially successful, and a general method for detecting hallucinations in LLMs is needed, even for questions to which humans might not know the answer.
ปรับแต่งบทสรุป
เขียนใหม่ด้วย AI
สร้างการอ้างอิง
แปลแหล่งที่มา
เป็นภาษาอื่น
สร้าง MindMap
จากเนื้อหาต้นฉบับ
ไปยังแหล่งที่มา
www.nature.com
Detecting hallucinations in large language models using semantic entropy - Nature
ข้อมูลเชิงลึกที่สำคัญจาก
by Sebastian Fa... ที่ www.nature.com 06-19-2024
https://www.nature.com/articles/s41586-024-07421-0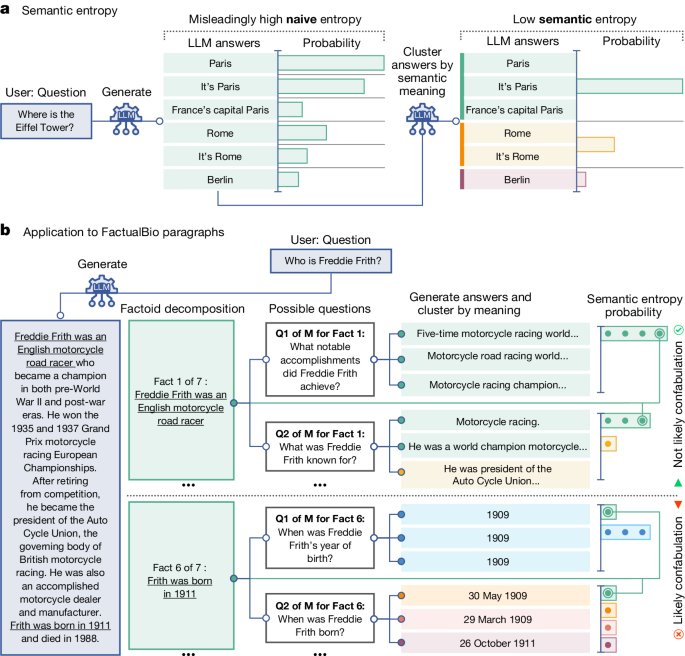
สอบถามเพิ่มเติม
How can the proposed entropy-based method be extended to detect other types of hallucinations beyond confabulations
What are the potential limitations or failure modes of the entropy-based approach, and how can they be addressed
How might the insights from this work on hallucination detection in language models be applied to other AI systems, such as those used in decision-making or safety-critical applications
© 2024 by Linnk AI