
본 연구 논문에서는 미국 메모리얼 슬론 케터링 암센터의 24,950명의 환자 데이터를 기반으로 암 환자의 예후 예측 모델 향상에 대한 연구 결과를 제시하고 있습니다. 연구팀은 자연어 처리 기법을 활용하여 비정형 데이터를 포함한 방대한 양의 환자 데이터를 통합하고 분석 가능한 형태로 변환했습니다. 이렇게 구축된 데이터셋인 MSK-CHORD는 기존 데이터셋에 비해 규모가 크고 다양한 변수를 포함하고 있어, 암 환자의 예후 예측 모델 개발 및 검증에 유용하게 활용될 수 있습니다.
연구 결과, 자연어 처리를 통해 추출된 질병 부위 정보와 같은 특징을 포함한 예측 모델이 유전체 데이터 또는 병기만을 사용한 모델보다 예측 정확도가 높은 것으로 나타났습니다. 또한, 705,241건의 방사선 보고서 분석을 통해 특정 장기로의 전이 예측 인자를 발견했으며, 면역 치료를 받은 폐 선암종 환자에서 SETD2 유전자 변이와 낮은 전이 가능성 사이의 연관성을 밝혀냈습니다.
본 연구는 대규모 실제 환자 데이터를 활용하여 암 환자의 예후 예측 모델을 개발하고 검증하는 데 유용한 프레임워크를 제시합니다. 특히, 자연어 처리 기법을 통해 비정형 데이터를 분석에 활용함으로써 예측 모델의 정확도를 향상시킬 수 있음을 보여줍니다.
연구의 중요성
본 연구는 대규모 실제 환자 데이터를 활용하여 암 환자의 예후를 정확하게 예측하는 모델을 개발할 수 있음을 보여주었습니다. 이는 개인 맞춤형 치료 계획 수립 및 질병 진행 관리에 기여할 수 있는 중요한 발견입니다.
연구의 한계점 및 향후 연구 방향
본 연구는 단일 기관의 데이터를 기반으로 수행되었기 때문에 연구 결과를 일반화하기 위해서는 다기관 데이터를 활용한 추가 연구가 필요합니다. 또한, 예측 모델의 정확도를 더욱 향상시키기 위해서는 더욱 정교한 자연어 처리 기법 및 기계 학습 알고리즘 개발이 필요합니다.
客製化摘要
使用 AI 重寫
產生引用格式
翻譯原文
翻譯成其他語言
產生心智圖
從原文內容
前往原文
www.nature.com
Automated real-world data integration improves cancer outcome prediction - Nature
從以下內容提煉的關鍵洞見
by Justin Jee,C... 於 www.nature.com 11-06-2024
https://www.nature.com/articles/s41586-024-08167-5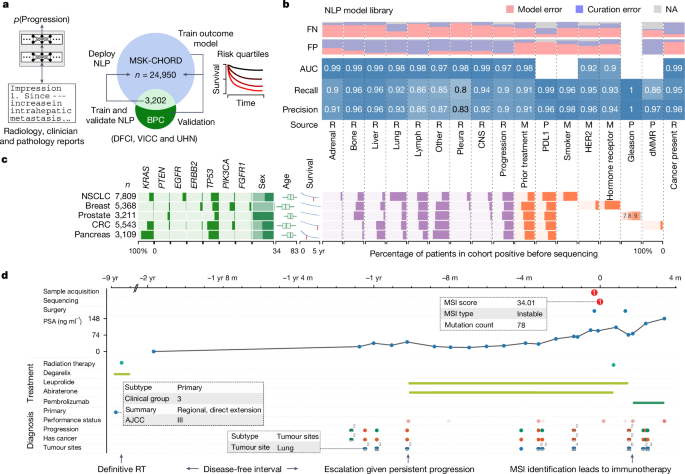
深入探究
본 연구에서 개발된 예측 모델을 실제 임상 환경에서 활용하기 위해서는 어떤 추가적인 검증 과정이 필요할까요?
환자 데이터의 프라이버시를 보호하면서 동시에 의료 인공지능 연구를 위한 데이터 공유를 활성화하기 위한 방안은 무엇일까요?
인공지능 기술의 발전이 암 치료 분야에 가져올 수 있는 긍정적 영향과 잠재적 위험은 무엇일까요?
© 2024 by Linnk AI