
登入
核心概念
NanoFlow是一個高性能的LLM服務框架,通過使用設備內並行、異步CPU調度和SSD卸載等技術,可以顯著提高LLM模型的吞吐量,比TensorRT-LLM最高達1.91倍。
摘要
NanoFlow是一個新的開源LLM服務框架,旨在通過各種優化技術來提高LLM模型的服務吞吐量。
具體來說:
- 使用設備內並行技術,可以充分利用GPU的計算能力。
- 採用異步CPU調度,可以提高CPU利用率。
- 利用SSD卸載技術,可以減少內存壓力。
根據NanoFlow的基準測試,它的吞吐量可以比TensorRT-LLM高出最高1.91倍。同時,它的延遲也非常低。
不過,這些測試都是在8個A100 80GB的DGX節點上進行的,我們還不知道它在消費級硬件和較小GPU上的表現如何。文檔也沒有提到是否支持量化技術。
作者表示,如果NanoFlow在24GB GPU和更小的硬件上也能表現出色,他會進一步撰文介紹。目前來看,對於LLM服務需求,vLLM仍然是最佳選擇。
客製化摘要
使用 AI 重寫
產生引用格式
翻譯原文
翻譯成其他語言
產生心智圖
從原文內容
前往原文
medium.com
NanoFlow: Faster than vLLM and TensorRT-LLM
統計資料
NanoFlow可以比TensorRT-LLM實現高達1.91倍的吞吐量提升。
引述
無
從以下內容提煉的關鍵洞見
by Benjamin Mar... 於 medium.com 09-01-2024
https://medium.com/@bnjmn_marie/nanoflow-faster-than-vllm-and-tensorrt-llm-f9f5718b9988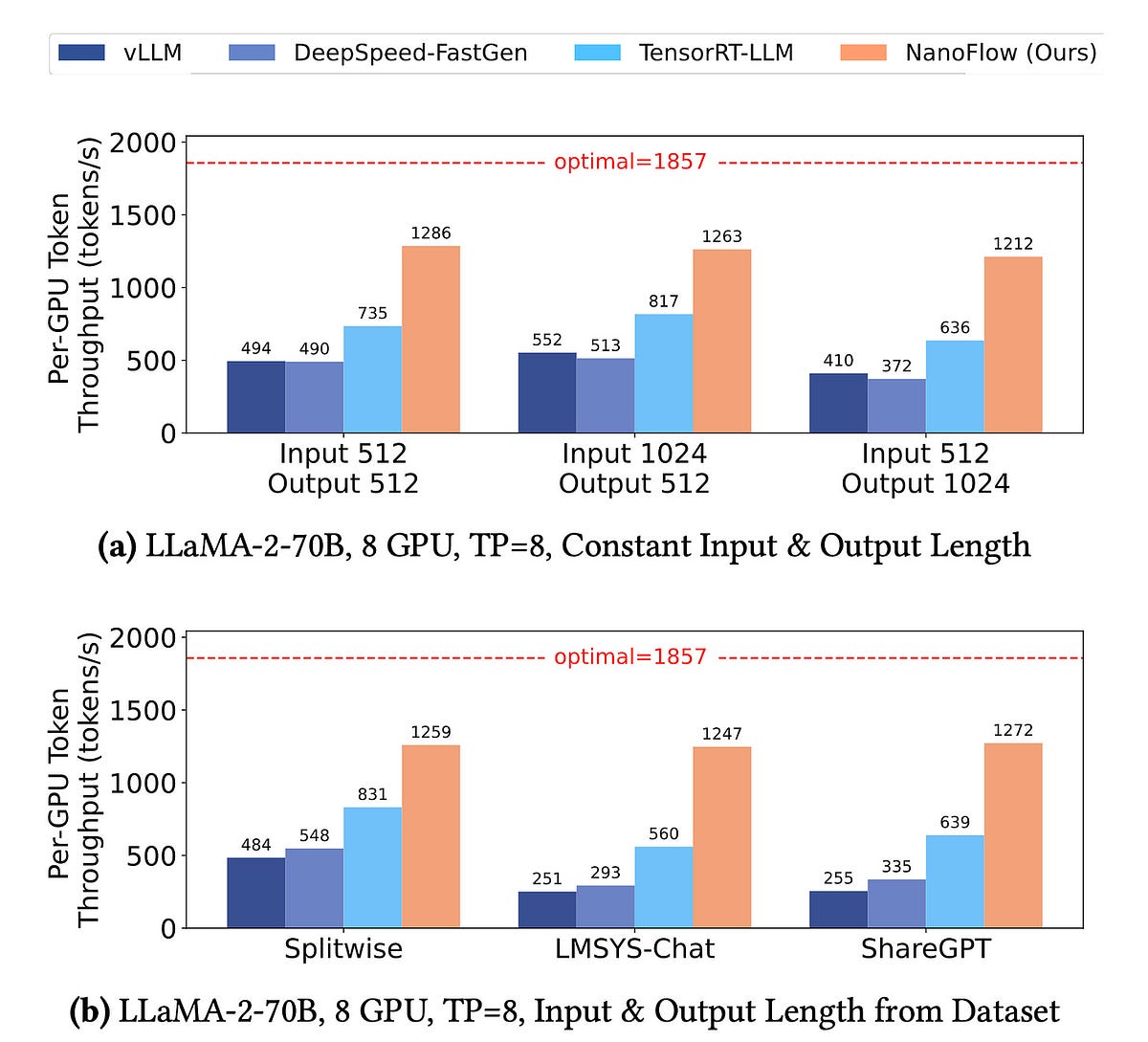
深入探究
NanoFlow是否支持量化技術,以及在不同硬件配置下的性能表現如何?
根據目前的文獻和資料,NanoFlow的文檔並未明確提到是否支持量化技術。量化技術通常用於減少模型大小和提高推理速度,特別是在資源有限的硬件上。至於在不同硬件配置下的性能表現,NanoFlow的基準測試主要是在8xA100 80GB的DGX節點上進行的,因此我們無法確定其在消費級硬件上的表現。這意味著,對於擁有24GB GPU或更小的硬件用戶,NanoFlow的性能可能會有所不同,具體效果仍需進一步測試和驗證。
除了吞吐量和延遲,NanoFlow在其他方面(如部署、易用性、擴展性等)相比其他LLM服務框架有何優勢和劣勢?
NanoFlow在部署和易用性方面的具體優勢和劣勢尚未詳細披露,但其開源特性和C++後端、Python前端的設計使得開發者能夠更靈活地進行集成和擴展。這種設計可能使得NanoFlow在某些情況下比其他框架更易於使用,特別是對於熟悉Python的開發者。然而,與vLLM等其他成熟框架相比,NanoFlow的文檔和社區支持可能尚不完善,這可能會影響其易用性和擴展性。此外,NanoFlow的高性能特性可能需要更高的硬件要求,這對於資源有限的用戶來說可能是一個劣勢。
除了LLM服務,NanoFlow的技術是否可以應用於其他類型的深度學習模型部署,或者是否可以啟發其他領域的高性能計算框架的設計?
NanoFlow所採用的技術,如設備內部並行處理、異步CPU調度和SSD卸載,具有廣泛的應用潛力,不僅限於大型語言模型(LLM)的服務。這些技術可以被應用於其他類型的深度學習模型部署,例如計算機視覺、語音識別等領域,因為這些領域同樣需要高吞吐量和低延遲的推理性能。此外,NanoFlow的設計理念和優化策略也可以啟發其他高性能計算框架的設計,特別是在如何有效利用硬件資源和提高計算效率方面。這些技術的應用可能會推動整個深度學習生態系統的發展,促進更高效的模型部署和推理。
0
© 2024 by Linnk AI