
Kirjaudu sisään
Keskeiset käsitteet
LLMの幻覚を検出する方法を開発した
Tiivistelmä
大規模言語モデル(LLM)を使ったテキスト生成システムは、自然な会話インターフェースを通じて広範な知識にアクセスできるため、経営者やプログラマーに熱心に受け入れられている。科学者たちも、LLMの使用と評価に引かれており、医薬品開発、材料設計、数学定理の証明などに応用している。しかし、LLMが質問(またはプロンプト)に対して、見かけ上は適切な答えのように見えるが、事実上正しくないまたは関連性のないテキストを生成する「幻覚」の問題が懸念されている。幻覚がどの程度の頻度で生成され、どのような文脈で生じるかは未だ明らかではないが、検出されないと誤りや害につながる可能性がある。Farquhar et al.は、この問題に取り組み、「confabulations」と呼ばれる特定のタイプの幻覚を検出する方法を開発した。
‘Fighting fire with fire’ — using LLMs to combat LLM hallucinations
Tilastot
LLMが生成する幻覚は、しばしば事実と異なる情報を含んでいる。
幻覚は定期的に発生し、検出されないと誤りや害につながる可能性がある。
Lainaukset
「LLMが質問(またはプロンプト)に対して、見かけ上は適切な答えのように見えるが、事実上正しくないまたは関連性のないテキストを生成する」
「幻覚がどの程度の頻度で生成され、どのような文脈で生じるかは未だ明らかではないが、検出されないと誤りや害につながる可能性がある」
Tärkeimmät oivallukset
by Karin Verspo... klo www.nature.com 06-19-2024
https://www.nature.com/articles/d41586-024-01641-0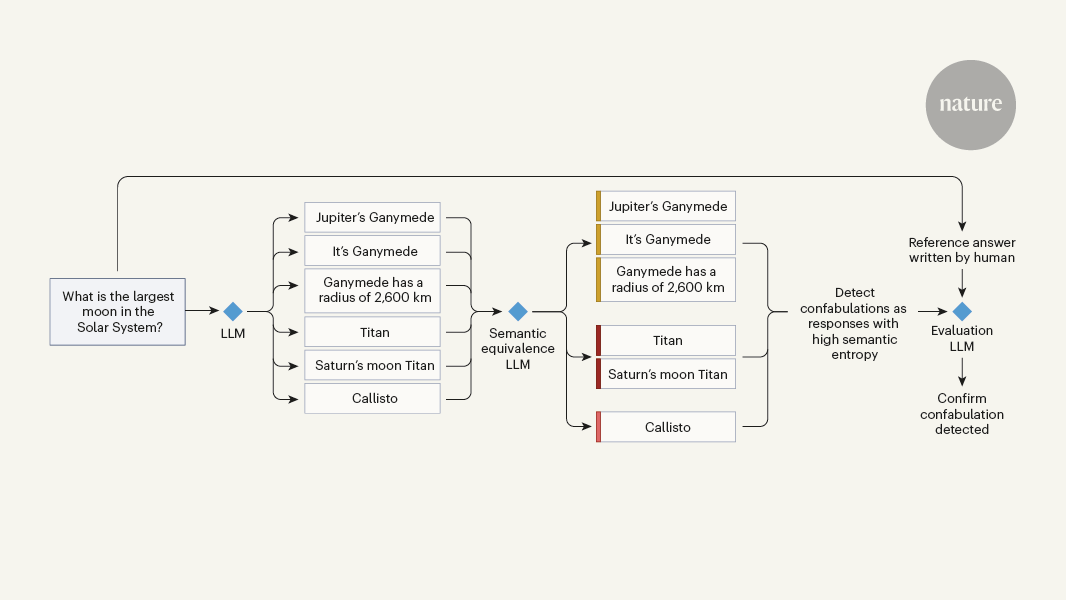
Syvällisempiä Kysymyksiä
LLMの幻覚を検出する他の方法はあるか?
Farquharらの研究では、特定の幻覚のサブクラスであるconfabulationsを検出する方法が開発されていますが、幻覚を検出する他の方法も存在します。例えば、幻覚が発生する際の言語モデルの学習データやアルゴリズムの改善によって、幻覚を減らすことができる可能性があります。また、幻覚が発生する特定の文脈やパターンを特定し、それらを回避するための制御策を導入することも有効なアプローチです。
LLMの幻覚が生成される根本的な原因は何か?
LLMの幻覚が生成される根本的な原因は、言語モデルが学習したデータの偏りや不完全さにあります。言語モデルは膨大な量のテキストデータから学習されるため、そのデータに含まれる誤った情報や矛盾した情報が幻覚の原因となります。また、言語モデルが文脈を正しく理解できない場合や、与えられたプロンプトに対して適切な回答を生成できない場合も幻覚が発生する可能性が高まります。
LLMの幻覚検出技術の発展は、人工知能の倫理的な課題にどのように影響するか?
LLMの幻覚検出技術の発展は、人工知能の倫理的な課題に重要な影響を与える可能性があります。幻覚が検出されることで、人工知能システムの信頼性が向上し、誤った情報に基づく意思決定や行動を防ぐことができます。また、幻覚の検出によって、人工知能システムの透明性や説明責任が向上し、その運用における倫理的なリスクを軽減することが期待されます。これにより、人工知能の社会的な受容性が高まり、より持続可能な技術の発展が促進される可能性があります。
0
Visualisoi tämä sivu
Luo huomaamattomalla tekoälyllä
Kääännä toiselle kielelle
Akateeminen Haku
Tuotteet | Materiaalit
© 2024 by Linnk AI