
Connexion
Unveiling the Inner Workings of ChatGPT: How and Why It Succeeds
Concepts de base
ChatGPT generates text by predicting reasonable continuations based on vast text data, using a probabilistic approach with controlled randomness to enhance creativity.
Résumé
ChatGPT operates by predicting the next word in a sequence based on probabilities derived from extensive text data. By balancing randomness with predictability, it generates coherent text that varies with each use. The model's success lies in its ability to estimate word probabilities without explicit examples, making it versatile for generating meaningful content. Neural nets underpinning ChatGPT are trained through machine learning to generalize from examples and adjust weights to minimize loss functions, enabling accurate predictions.
What Is ChatGPT Doing … and Why Does It Work?
Stats
"175 billion of them."
"60,650."
"2190."
"17 neurons."
Citations
Idées clés tirées de
by Nicos Kekchi... à writings.stephenwolfram.... 02-26-2024
https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/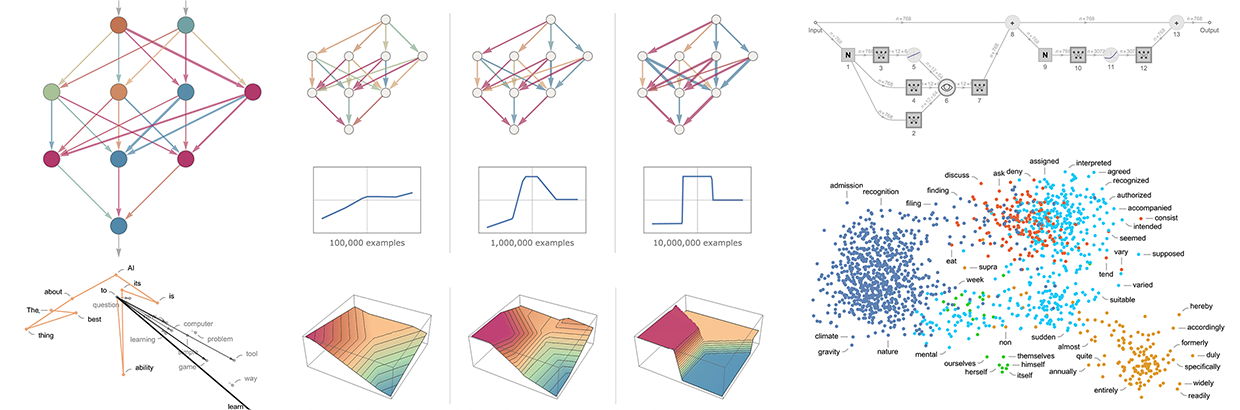
Questions plus approfondies
How does ChatGPT's approach compare to traditional language models?
ChatGPT differs from traditional language models in its ability to generate text by focusing on producing a "reasonable continuation" of the given text. It scans vast amounts of human-written text to determine the most likely word that should follow based on what has been written before. This method allows ChatGPT to generate coherent and meaningful text that mimics human writing styles. In contrast, traditional language models may not have the same level of sophistication and capability to produce contextually relevant responses.
Does the reliance on randomness impact the quality of generated text?
The reliance on randomness in ChatGPT's text generation process can have both positive and negative impacts on the quality of generated text. By occasionally selecting lower-ranked words instead of always choosing the highest-ranked word, ChatGPT introduces an element of creativity and variability into its output, making it more interesting and less repetitive. However, this randomness can also lead to inconsistencies or occasional nonsensical outputs in generated text. Overall, when used judiciously with a suitable "temperature" parameter setting, randomness can enhance the quality and diversity of generated content.
How can neural nets' training process be improved for more efficient learning?
To improve neural nets' training process for more efficient learning, several strategies can be implemented:
Optimization Algorithms: Using advanced optimization algorithms like stochastic gradient descent (SGD), Adam optimization, or RMSprop can help converge faster towards optimal weights during training.
Regularization Techniques: Incorporating regularization techniques such as L1/L2 regularization or dropout layers helps prevent overfitting and improves generalization.
Hyperparameter Tuning: Fine-tuning hyperparameters like learning rate, batch size, activation functions, etc., through grid search or random search methods can optimize model performance.
Data Augmentation: Increasing dataset size through data augmentation techniques like rotation, flipping images/texts horizontally/vertically aids in better generalization.
Early Stopping: Implementing early stopping mechanisms based on validation loss helps prevent overfitting while saving computational resources.
Transfer Learning: Leveraging pre-trained models or transfer learning approaches accelerates training by utilizing knowledge learned from similar tasks/models.
By incorporating these strategies into neural net training processes effectively enhances efficiency and overall performance during model development and deployment stages
0
Visualiser cette page
Générer avec une IA indétectable
Traduire dans une autre langue
Recherche académique
Produits | Ressources
© 2024 by Linnk AI