
Sign In
Comprehensive Comparison of Top AI Language Models: LLama 3, Claude 3, GPT4 Omni, Gemini 1.5 Pro-Light, and More
Core Concepts
The article provides a detailed comparison of the latest top AI language models, including their multimodal capabilities, context length, benchmark performance, and pricing, to help users make informed decisions.
Abstract
The article compares the latest top AI language models, including LLama 3, Claude 3, GPT4 Omni, and Gemini 1.5 Pro-Light, across various dimensions:
Multimodality:
- All models except LLama 3 have image processing capabilities, while Gemini 1.5 and GPT4 Omni can also process audio and video.
- GPT4 Omni is the only model with full multimodal capabilities, though not yet available through the API.
Context Length:
- Gemini 1.5 has the largest context window of 2M tokens, followed by Claude 3 with 1M tokens.
- LLama 3 has a smaller context window of 8K tokens but is optimized for efficient use of the available context.
Benchmarks:
- The models perform similarly on text-based benchmarks, with GPT4 Omni and Gemini 1.5 Flash standing out for their fast response times despite their added capabilities.
- The models also show comparable performance on vision-based tasks.
Pricing:
- GPT4 Omni is the most expensive model, while LLama 3, Claude 3 Haiku, and Gemini 1.5 Flash offer the best performance-to-cost ratio for intermediate and simple tasks.
The article provides a comprehensive overview to help users understand the trade-offs and select the most suitable model for their needs.
Customize Summary
Rewrite with AI
Generate Citations
Translate Source
To Another Language
Generate MindMap
from source content
Visit Source
medium.com
Battle of the TOP — LLama 3, Claude 3, GPT4 Omni, Gemini 1.5 Pro-Light and more
Stats
Gemini 1.5 has a context window of 2M tokens.
Claude 3 has a context window of 1M tokens.
LLama 3 has a context window of 8K tokens.
GPT4 Omni is the most expensive model among the ones compared.
LLama 3, Claude 3 Haiku, and Gemini 1.5 Flash offer the best performance-to-cost ratio.
Quotes
"Gemini 1.5 both versions and GPT 4 Omni stand out for being able to process audio and video(sort of, snapshots of it)."
"And right now only GPT 4 Omni has all in and out of these modalities, although they are not available in their api today with promise later this year."
"LLama 3 of course is also very impressive considering its size compared to others and its very on par scores."
Key Insights Distilled From
by at medium.com 05-15-2024
https://medium.com/@daniellefranca96/battle-of-the-top-llama-3-claude-3-gpt4-omni-gemini-1-5-pro-light-and-more-3ff560cf6b58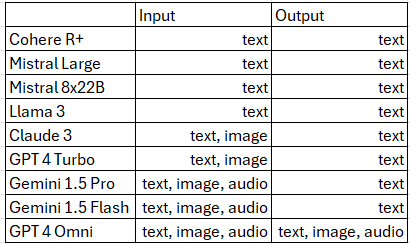
Deeper Inquiries
How do the models compare in terms of their ability to handle complex, multi-step tasks or reasoning?
In terms of handling complex, multi-step tasks or reasoning, the models differ in their capabilities. LLama 3 stands out for its optimized use of context despite having a smaller window size. Gemini 1.5 and GPT 4 Omni excel in processing audio and video data, giving them an edge in multimodal tasks. GPT 4 Omni, with promises of additional modalities later, seems to have the most comprehensive range of capabilities. However, all models seem to perform well in text and vision tasks, with some variations in response latency. Overall, LLama 3, Gemini 1.5, and GPT 4 Omni show promise in handling complex tasks efficiently.
What are the potential limitations or biases of these models, and how can they be addressed?
One potential limitation of these models is the high cost associated with some of them, particularly GPT 4 Omni. This could restrict access for smaller businesses or organizations. Another limitation could be biases in the data used to train these models, leading to biased outputs or decisions. To address these limitations, efforts should be made to make advanced AI models more affordable and accessible. Additionally, continuous monitoring and auditing of the training data can help mitigate biases and ensure fair and accurate results.
How might the development of even more advanced multimodal AI systems impact various industries and applications in the future?
The development of more advanced multimodal AI systems is likely to have a significant impact on various industries and applications in the future. For example, in healthcare, these systems could improve diagnostics by integrating data from multiple sources like images, text, and patient records. In marketing, they could enhance customer engagement by analyzing both visual and textual content. In autonomous vehicles, multimodal AI could improve decision-making by processing diverse sensory inputs. Overall, the integration of advanced multimodal AI systems is expected to revolutionize industries by enabling more efficient and effective problem-solving across different domains.
0
Products | Resources
© 2024 by Linnk AI