Detecting Hallucinations in Large Language Models: A Novel Approach
Core Concepts
Detecting a specific subclass of hallucinations, termed confabulations, in large language models to address the problem of factually incorrect or irrelevant responses.
Abstract
The content discusses the problem of "hallucinations" in text-generation systems powered by large language models (LLMs). Hallucinations occur when an LLM responds to a prompt with text that seems plausible but is factually incorrect or irrelevant. This can lead to errors and potential harm if undetected.
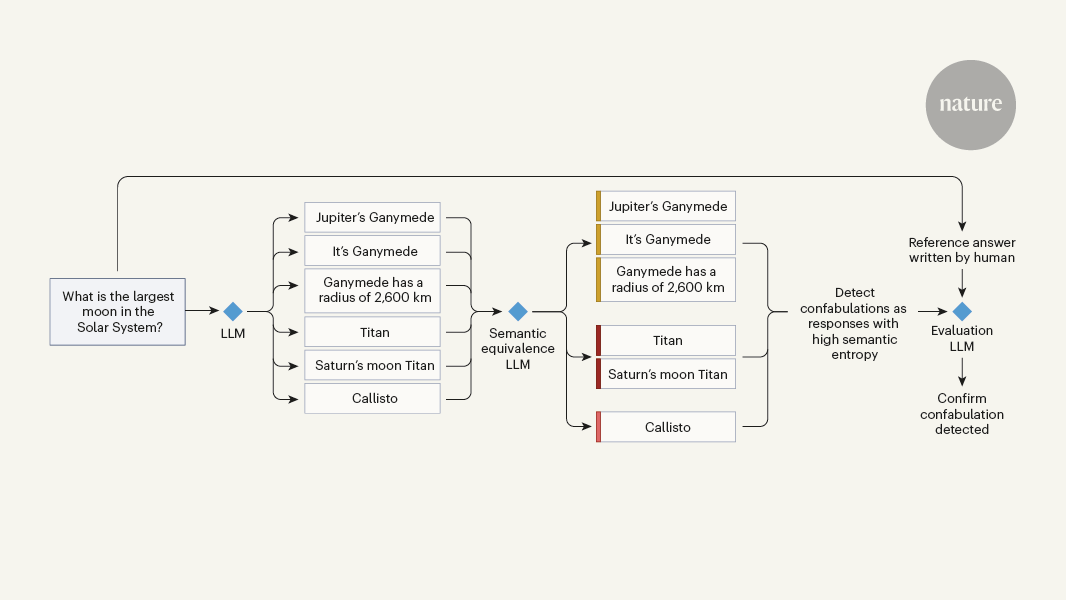
The article highlights that the frequency and contexts of hallucinations in LLMs remain to be determined, but it is clear that they occur regularly. To address this issue, the authors of a paper in Nature, Farquhar et al., have developed a method for detecting a specific subclass of hallucinations, termed confabulations.
The key points are:
- LLMs have been widely adopted for their ability to provide easy access to extensive knowledge through natural conversation.
- A major concern with LLMs is the problem of "hallucinations," where the model generates plausible but factually incorrect or irrelevant responses.
- The frequency and contexts of hallucinations in LLMs are still being investigated, but they are known to occur regularly and can lead to errors and harm if undetected.
- Farquhar et al. have proposed a novel method to detect a specific type of hallucination, called confabulations, in LLMs.
Translate Source
To Another Language
Generate MindMap
from source content
Visit Source
www.nature.com
‘Fighting fire with fire’ — using LLMs to combat LLM hallucinations
Stats
"Text-generation systems powered by large language models (LLMs) have been enthusiastically embraced by busy executives and programmers alike, because they provide easy access to extensive knowledge through a natural conversational interface."
"A key concern for such uses relates to the problem of 'hallucinations', in which the LLM responds to a question (or prompt) with text that seems like a plausible answer, but is factually incorrect or irrelevant."
Quotes
"How often hallucinations are produced, and in what contexts, remains to be determined, but it is clear that they occur regularly and can lead to errors and even harm if undetected."
"In a paper in Nature, Farquhar et al.5 tackle this problem by developing a method for detecting a specific subclass of hallucinations, termed confabulations."
Deeper Inquiries
What are the potential implications of undetected hallucinations in LLMs for various applications, such as drug discovery, materials design, or mathematical theorem-proving?
Undetected hallucinations in LLMs can have significant implications across various applications. In drug discovery, relying on inaccurate information generated by LLM hallucinations could lead to the identification of ineffective or even harmful compounds, potentially wasting resources and delaying the development of new medications. Similarly, in materials design, if LLMs produce hallucinations that suggest certain properties or behaviors of materials that are incorrect, it could result in the creation of subpar products or materials with unexpected flaws. In the context of mathematical theorem-proving, hallucinations could lead researchers down incorrect paths, resulting in flawed proofs and erroneous conclusions. Overall, the implications of undetected hallucinations in LLMs can range from inefficiencies and setbacks to potentially serious consequences in critical fields like drug discovery, materials design, and mathematical theorem-proving.
How can the proposed method for detecting confabulations be extended to identify other types of hallucinations in LLMs?
The method proposed by Farquhar et al. for detecting confabulations in LLMs can serve as a foundation for identifying other types of hallucinations as well. By analyzing the patterns and characteristics of confabulations, researchers can develop algorithms that can be trained to recognize similar inconsistencies in LLM-generated text. This approach could involve creating a comprehensive dataset of known hallucinations across different domains and using machine learning techniques to classify and detect these anomalies. Additionally, researchers can explore incorporating contextual information and domain-specific knowledge to enhance the detection of hallucinations in LLM outputs. By iteratively refining the detection method based on feedback and evaluation, it can be extended to identify a broader range of hallucination types beyond confabulations, improving the overall reliability of LLM-generated responses.
What other approaches or techniques could be explored to improve the reliability and trustworthiness of LLMs in generating accurate and relevant responses?
In addition to the proposed method for detecting hallucinations, several other approaches and techniques could be explored to enhance the reliability and trustworthiness of LLMs in generating accurate and relevant responses. One approach is to implement post-generation verification mechanisms that assess the coherence and factual accuracy of LLM outputs. This could involve leveraging external knowledge sources or conducting fact-checking procedures to validate the information provided by the LLM. Furthermore, fine-tuning LLMs on domain-specific data and incorporating constraints or guidelines during text generation can help steer the model towards producing more reliable responses. Collaborative filtering techniques, where multiple LLMs generate responses independently and then cross-validate each other's outputs, can also improve the overall accuracy and robustness of the generated text. By combining these approaches and continuously refining the training and evaluation processes, the reliability and trustworthiness of LLMs can be enhanced, making them more dependable tools across various applications.