
Sign In
Core Concepts
대규모 언어 모델(LLM)이 온라인 텍스트와 이미지를 크게 변화시킬 것이 분명해짐에 따라, 이러한 모델 생성 콘텐츠를 무분별하게 학습 데이터로 사용하면 모델 자체에 돌이킬 수 없는 결함이 발생한다.
Abstract
이 논문은 안정적인 확산 모델, GPT-2, GPT-3, GPT-4 등 최신 생성 AI 기술이 온라인 콘텐츠 생태계를 크게 변화시킬 것이라는 점을 지적한다. 특히 이러한 대규모 언어 모델(LLM)이 생성한 콘텐츠를 무분별하게 학습 데이터로 사용하면 모델 자체에 돌이킬 수 없는 결함이 발생하는 '모델 붕괴' 현상이 일어날 수 있다고 설명한다.
이 현상은 LLM뿐만 아니라 변분 자동 인코더(VAE)와 가우시안 혼합 모델(GMM)에서도 나타날 수 있으며, 이에 대한 이론적 직관을 제시한다. 결국 웹에서 수집한 대규모 데이터를 활용하여 모델을 학습하려면 이러한 모델 붕괴 문제를 심각하게 고려해야 한다고 강조한다. 사용자와의 진정한 상호작용에 대한 데이터가 점점 더 가치 있게 될 것이라고 전망한다.
Customize Summary
Rewrite with AI
Generate Citations
Translate Source
To Another Language
Generate MindMap
from source content
Visit Source
www.nature.com
AI models collapse when trained on recursively generated data - Nature
Stats
안정적인 확산 모델, GPT-2, GPT-3, GPT-4 등 최신 생성 AI 기술이 온라인 콘텐츠 생태계를 크게 변화시킬 것이 분명하다.
모델 생성 콘텐츠를 무분별하게 학습 데이터로 사용하면 모델 자체에 돌이킬 수 없는 결함이 발생하는 '모델 붕괴' 현상이 일어날 수 있다.
이 현상은 LLM뿐만 아니라 VAE와 GMM에서도 나타날 수 있다.
Quotes
"대규모 언어 모델(LLM)이 온라인 텍스트와 이미지를 크게 변화시킬 것이 분명해짐에 따라, 이러한 모델 생성 콘텐츠를 무분별하게 학습 데이터로 사용하면 모델 자체에 돌이킬 수 없는 결함이 발생한다."
"결국 웹에서 수집한 대규모 데이터를 활용하여 모델을 학습하려면 이러한 모델 붕괴 문제를 심각하게 고려해야 한다."
Key Insights Distilled From
by Ilia Shumail... at www.nature.com 07-24-2024
https://www.nature.com/articles/s41586-024-07566-y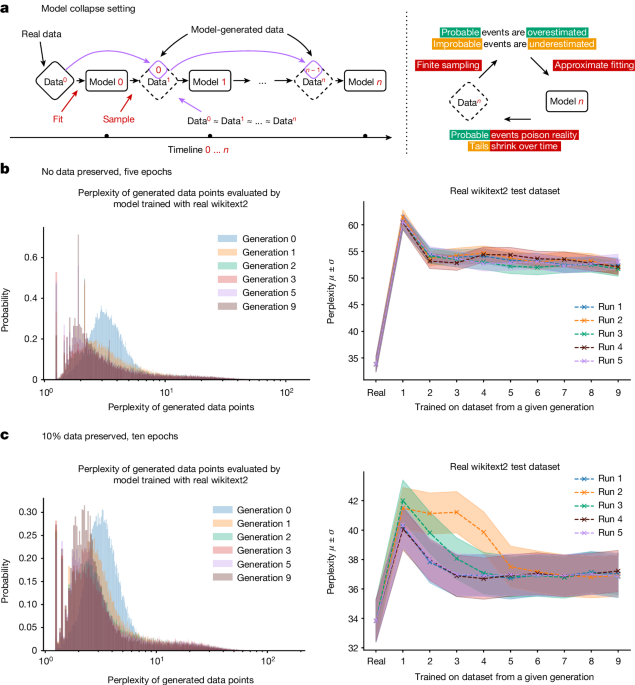
Deeper Inquiries
AI 모델 학습 시 모델 생성 콘텐츠의 사용을 어떻게 제한할 수 있을까?
모델 생성 콘텐츠의 사용을 제한하기 위해서는 데이터의 다양성과 원본 분포를 유지하는 것이 중요합니다. 이를 위해 모델이 생성한 콘텐츠를 학습 데이터로 재사용하는 것을 제한하거나, 생성된 콘텐츠의 비중을 조절하여 모델이 원본 데이터의 특성을 유지하도록 할 수 있습니다. 또한, 생성된 콘텐츠와 실제 데이터를 구분하여 모델이 두 종류의 데이터를 구별하도록 하는 방법도 효과적일 수 있습니다.
모델 붕괴 현상을 방지하기 위한 다른 접근 방식은 무엇이 있을까?
모델 붕괴 현상을 방지하기 위한 다른 접근 방식으로는 데이터의 품질을 유지하고 모델이 생성한 콘텐츠와 실제 데이터를 구분하는 것이 중요합니다. 또한, 모델이 생성한 콘텐츠를 다시 학습 데이터로 사용하지 않도록 하는 방법이 효과적일 수 있습니다. 또한, 모델이 생성한 콘텐츠의 영향을 줄이기 위해 regularization 기법을 도입하거나, 생성된 콘텐츠의 품질을 평가하여 모델의 성능을 유지하는 방법도 고려할 수 있습니다.
사용자와의 진정한 상호작용 데이터가 가치 있게 되는 이유는 무엇일까?
사용자와의 진정한 상호작용 데이터가 가치 있게 되는 이유는 모델이 생성한 콘텐츠와의 차이를 인식하고, 모델이 실제 상황에서 어떻게 작동해야 하는지를 학습할 수 있기 때문입니다. 이러한 데이터는 모델이 현실 세계에서 적합한 결정을 내리고 적절한 행동을 취할 수 있도록 도와줍니다. 또한, 사용자와의 상호작용 데이터는 모델이 사람들의 요구와 선호도를 이해하고, 그에 맞게 적절한 응답을 생성할 수 있도록 도와줍니다. 따라서, 사용자와의 진정한 상호작용 데이터는 모델의 성능을 향상시키고, 모델이 현실 세계에서 더 나은 결과를 얻을 수 있도록 도와줍니다.
0
Products | Resources
© 2024 by Linnk AI