
Sign In
Detecting Fabricated Outputs in Large Language Models Using Semantic Entropy
Core Concepts
Large language models often generate false or unsubstantiated outputs, known as "hallucinations", which prevent their adoption in critical domains. This work proposes a general method to detect a subset of hallucinations, called "confabulations", by estimating the semantic entropy of model outputs.
Abstract
The content discusses the problem of hallucinations in large language models (LLMs) such as ChatGPT and Gemini. LLMs can sometimes generate false or unsubstantiated answers, which poses a significant challenge for their adoption in diverse fields, including legal, news, and medical domains.
The authors propose a new method to detect a subset of hallucinations, called "confabulations", which are arbitrary and incorrect generations. The key idea is to compute the uncertainty of the model's outputs at the level of meaning rather than specific sequences of words, using an entropy-based approach.
The proposed method has several advantages:
It works across datasets and tasks without requiring a priori knowledge of the task or task-specific data.
It can robustly generalize to new tasks not seen before.
By detecting when a prompt is likely to produce a confabulation, the method helps users understand when they must take extra care with LLMs, enabling new possibilities for using these models despite their unreliability.
The authors highlight that encouraging truthfulness through supervision or reinforcement has only been partially successful, and a general method for detecting hallucinations in LLMs is needed, even for questions to which humans might not know the answer.
Detecting hallucinations in large language models using semantic entropy - Nature
Stats
Large language model (LLM) systems, such as ChatGPT1 or Gemini2, can show impressive reasoning and question-answering capabilities but often 'hallucinate' false outputs and unsubstantiated answers3,4.
Answering unreliably or without the necessary information prevents adoption in diverse fields, with problems including fabrication of legal precedents5 or untrue facts in news articles6 and even posing a risk to human life in medical domains such as radiology7.
Quotes
"Encouraging truthfulness through supervision or reinforcement has been only partially successful8."
"Our method addresses the fact that one idea can be expressed in many ways by computing uncertainty at the level of meaning rather than specific sequences of words."
Key Insights Distilled From
by Sebastian Fa... at www.nature.com 06-19-2024
https://www.nature.com/articles/s41586-024-07421-0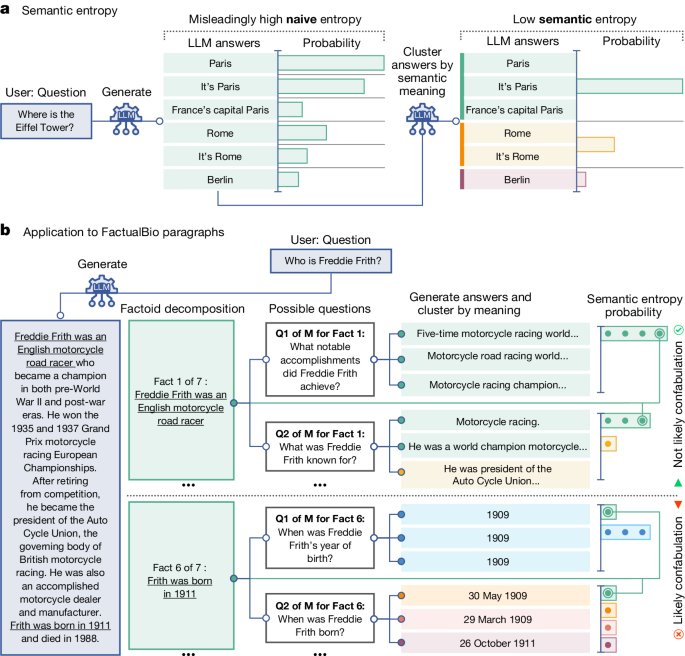
Deeper Inquiries
How can the proposed entropy-based method be extended to detect other types of hallucinations beyond confabulations
The proposed entropy-based method can be extended to detect other types of hallucinations beyond confabulations by incorporating additional semantic features and context analysis. By expanding the scope of semantic entropy calculations to include a wider range of linguistic patterns and meanings, the model can learn to identify various types of hallucinations, such as delusions, distortions, or misinterpretations. Introducing more sophisticated machine learning algorithms that can capture nuanced semantic relationships and inconsistencies in the generated text can enhance the detection of diverse hallucination types. Additionally, integrating external knowledge sources or domain-specific ontologies can provide contextual information to improve the model's ability to differentiate between genuine responses and hallucinations across different domains or topics.
What are the potential limitations or failure modes of the entropy-based approach, and how can they be addressed
Potential limitations or failure modes of the entropy-based approach include the challenge of defining a universal threshold for determining when a response is a hallucination. The method may struggle with detecting subtle or context-dependent hallucinations that do not exhibit high semantic entropy. To address this, researchers can explore adaptive thresholding techniques that adjust the uncertainty threshold based on the complexity of the input prompt or the model's confidence level. Moreover, incorporating human feedback mechanisms or ensemble learning approaches can help refine the detection process by leveraging human judgment or combining multiple detection strategies to mitigate false positives or negatives. Regularly updating the model with new data and continuously evaluating its performance on diverse datasets can also help overcome limitations and improve the robustness of the hallucination detection system.
How might the insights from this work on hallucination detection in language models be applied to other AI systems, such as those used in decision-making or safety-critical applications
The insights gained from this work on hallucination detection in language models can be applied to other AI systems, particularly those used in decision-making or safety-critical applications, to enhance their reliability and trustworthiness. By integrating similar uncertainty estimation techniques based on semantic entropy, decision-making AI systems can assess the confidence and accuracy of their predictions, enabling them to flag uncertain or potentially erroneous outputs for further scrutiny. In safety-critical applications like autonomous vehicles or medical diagnosis systems, incorporating hallucination detection mechanisms can help prevent catastrophic errors caused by false information or misleading outputs. By promoting transparency and accountability in AI systems through robust hallucination detection methods, stakeholders can have greater confidence in the decisions made by these systems, ultimately improving their usability and effectiveness in real-world scenarios.
0
More on Hallucination Detection in Large Language Models
KnowHalu: A Novel Approach for Detecting Hallucinations in Text Generated by Large Language Models
SHROOM-INDElab's Hallucination Detection System for SemEval-2024 Task 6: Zero- and Few-Shot LLM-Based Classification
Detecting and Forecasting Hallucinations in Large Language Models via State Transition Dynamics
Products | Resources
Read more
- spatialyze-geospatial-video-analytics-system-with-spatial-aware-optimizations
- federated-learning-for-spectrum-occupancy-detection
- a-polystore-architecture-using-knowledge-graphs-for-querying-heterogeneous-data-stores
- 子供たちの共同創作を通じたselエージェントのデザイン機会を探る
- dcnfis-deep-convolutional-neuro-fuzzy-inference-system
- 任意の平面コンパクト領域のメディアルパラメータ化と二極子による処理
- exploring-foundation-models-in-smart-agriculture-opportunities-and-challenges
- 多モーダル大規模言語モデルによる現実世界の事実チェックをサポートする
© 2024 by Linnk AI