
Sign In
Core Concepts
再帰的に生成されたデータでAIモデルを訓練すると、モデルが不可逆的な欠陥に陥る可能性がある。
Abstract
この論文では、大規模言語モデル(LLM)やバリエーショナル・オートエンコーダー(VAE)、ガウス混合モデル(GMM)などの生成型AIモデルが、インターネットから収集した再帰的に生成されたデータで訓練されると、不可逆的な欠陥に陥る可能性について論じている。
具体的には、モデル生成のデータに既存のモデル出力が含まれると、元のデータ分布の裾野が消失する「モデル崩壊」と呼ばれる現象が起こることが示されている。この問題は理論的に説明され、様々なモデルで一般的に起こりうることが明らかにされている。
この問題に対処するためには、ユーザーとシステムの真正な相互作用に関するデータの価値が高まると指摘されている。インターネットからスクレイピングしたデータにはLLM生成のコンテンツが含まれるため、そのようなデータだけでは持続可能なモデル構築は困難になる可能性がある。
Customize Summary
Rewrite with AI
Generate Citations
Translate Source
To Another Language
Generate MindMap
from source content
Visit Source
www.nature.com
AI models collapse when trained on recursively generated data - Nature
Stats
LLMやVAE、GMMなどの生成モデルは、再帰的に生成されたデータで訓練すると、元のデータ分布の裾野が消失する可能性がある。
Quotes
"再帰的に生成されたデータでAIモデルを訓練すると、モデルが不可逆的な欠陥に陥る可能性がある。"
"インターネットからスクレイピングしたデータにはLLM生成のコンテンツが含まれるため、そのようなデータだけでは持続可能なモデル構築は困難になる可能性がある。"
Key Insights Distilled From
by Ilia Shumail... at www.nature.com 07-24-2024
https://www.nature.com/articles/s41586-024-07566-y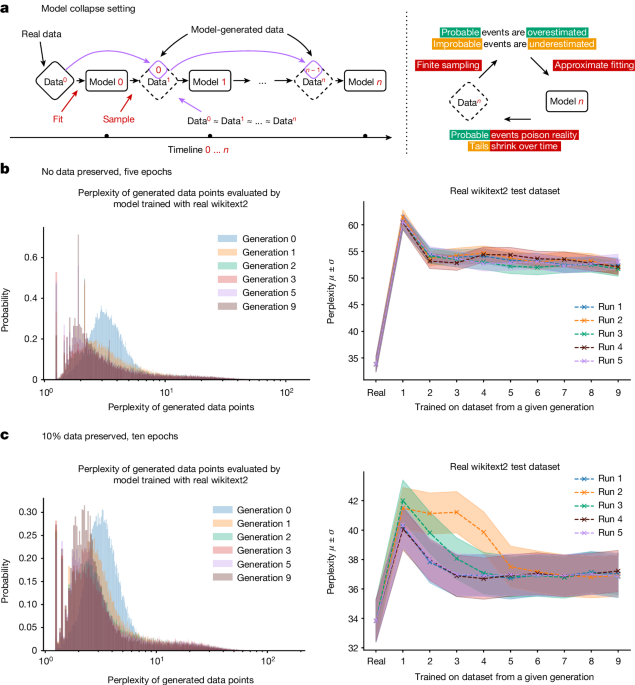
Deeper Inquiries
再帰的生成データの問題に対する具体的な解決策はあるか?
再帰的生成データの問題に対処するための具体的な解決策として、モデルの訓練時に生成されるデータの品質を向上させるための制約やフィルタリング手法を導入することが考えられます。例えば、生成されたデータの分布を監視し、異常なデータや極端なデータがモデルに与える影響を制限することで、モデルの崩壊を防ぐことができるかもしれません。さらに、再帰的生成データの問題に対処するためには、データの収集段階から慎重に品質管理を行い、不適切なデータがモデルに影響を与えることを事前に防ぐことも重要です。
LLMが生成したコンテンツと人間が生成したコンテンツを効果的に識別する方法はあるか?
LLMが生成したコンテンツと人間が生成したコンテンツを効果的に識別するためには、信頼性の高い検証手法やツールを開発することが重要です。例えば、生成されたコンテンツには特定のパターンや文法的な特徴が存在する可能性がありますので、これらを検出するための自然言語処理技術や機械学習アルゴリズムを活用することが考えられます。また、人間が生成したコンテンツとの比較や、コンテンツの背景や文脈を考慮することで、より正確な識別が可能となるかもしれません。
この問題は、AIシステムの信頼性や倫理性にどのような影響を及ぼすと考えられるか?
再帰的生成データの問題がAIシステムに与える影響は、その信頼性や倫理性に深刻な懸念を引き起こす可能性があります。例えば、モデルの崩壊によって生成されたコンテンツが誤った情報を拡散し、人々の意見や行動に影響を与えることが考えられます。また、人間が生成したコンテンツとの区別がつかない場合、信頼性の高い情報源との混同や偽情報の拡散が起こる可能性があります。このような状況下では、AIシステムの信頼性や倫理性が損なわれるだけでなく、社会全体の情報環境やコミュニケーションにも深刻な影響を及ぼす可能性があるため、この問題には真剣に取り組む必要があります。
0
Products | Resources
© 2024 by Linnk AI