
Meta's Groundbreaking AI Translation Model Aims to Serve Underrepresented Languages Worldwide
The article discusses Meta's (formerly Facebook) efforts to develop a more inclusive and comprehensive machine translation model called No Language Left Behind (NLLB). Existing machine translation models can only interpret a small fraction of the world's languages, as they require large amounts of online data to train, which is often lacking for many underrepresented languages.
The NLLB project aims to address this gap by creating a publicly available model that can translate between 204 languages, including those used in low- and middle-income countries. This is a significant advancement, as it has the potential to enhance communication and break down barriers posed by language differences, particularly for marginalized communities.
The article highlights the importance of this project in promoting global accessibility and inclusivity in the field of machine translation. By expanding the language coverage, the NLLB model can facilitate better cross-cultural understanding and communication, which is crucial for various applications, such as education, healthcare, and international collaboration.
Samenvatting aanpassen
Herschrijven met AI
Citaten genereren
Bron vertalen
Naar een andere taal
Mindmap genereren
vanuit de broninhoud
Bron bekijken
www.nature.com
Meta’s AI translation model embraces overlooked languages
Belangrijkste Inzichten Gedestilleerd Uit
by David I. Ade... om www.nature.com 06-05-2024
https://www.nature.com/articles/d41586-024-00964-2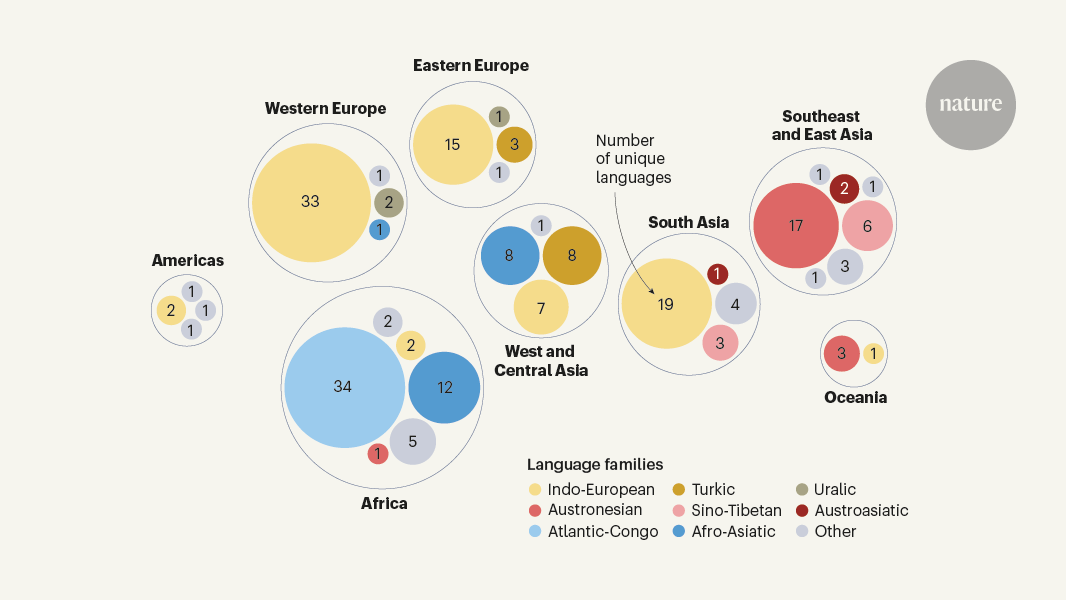
Diepere vragen
How can the NLLB model be further improved to ensure accurate and culturally-sensitive translations for all 204 languages?
What potential challenges or limitations might arise in deploying the NLLB model in low-resource settings, and how can they be addressed?
How can the development of the NLLB model inspire similar efforts to promote linguistic diversity and inclusion in other areas of technology and digital infrastructure?
© 2024 by Linnk AI