
Logg Inn
Grunnleggende konsepter
メタが開発した多言語翻訳モデルNLLBは、オンラインデータが不足している低・中所得国の言語204種類に対応し、言語の壁を越えたコミュニケーションを促進する。
Sammendrag
メタは、人工知能を使った機械翻訳モデルを開発する「No Language Left Behind」(NLLB)プロジェクトを立ち上げた。従来の機械翻訳モデルは、オンラインデータの不足から、世界の言語の一部しか翻訳できないという課題があった。
NLLBモデルは、204の言語に対応しており、特に低・中所得国で使用されている言語に焦点を当てている。これにより、言語の違いによるコミュニケーションの障壁を克服し、より多くの人々が情報にアクセスできるようになることが期待されている。
NLLBモデルは無料で一般に公開されており、研究者や開発者が活用できる。言語の多様性を尊重し、言語の壁を越えたコミュニケーションを促進することが、このプロジェクトの目的である。
Customize Summary
Rewrite with AI
Generate Citations
Translate Source
To Another Language
Generate MindMap
from source content
Visit Source
www.nature.com
Meta’s AI translation model embraces overlooked languages
Statistikk
機械翻訳モデルNLLBは204の言語に対応している。
多くの低・中所得国の言語を含んでいる。
Sitater
「言語の違いによるコミュニケーションの障壁を克服し、より多くの人々が情報にアクセスできるようになることが期待されている」
Viktige innsikter hentet fra
by David I. Ade... klokken www.nature.com 06-05-2024
https://www.nature.com/articles/d41586-024-00964-2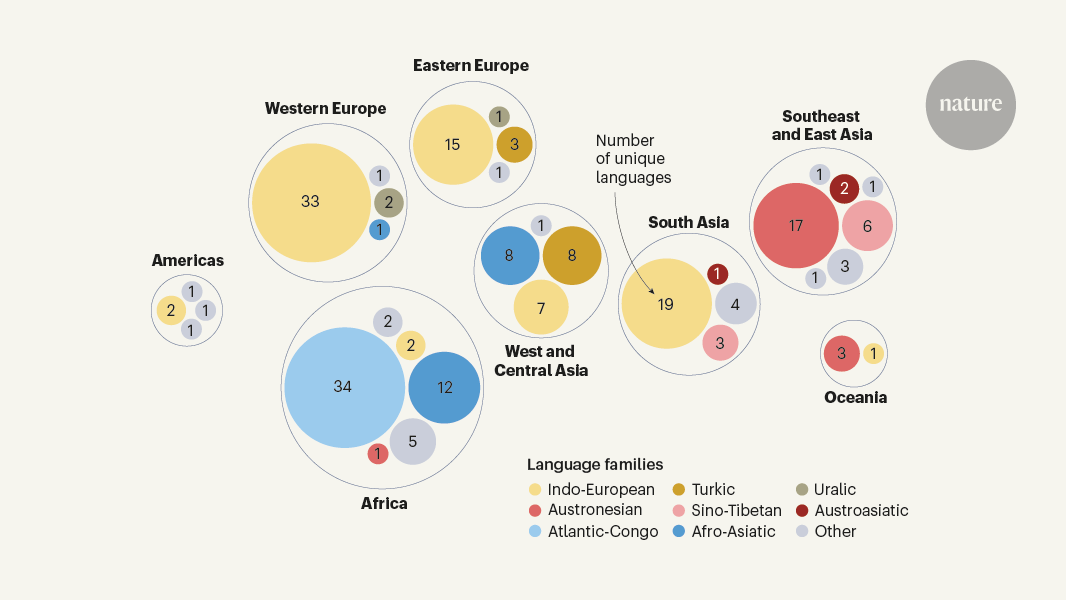
Dypere Spørsmål
NLLBモデルの精度や性能はどのように評価されているか。
NLLBモデルの精度と性能は、論文や専門家による評価、および実際の使用状況に基づいて評価されています。一般的に、翻訳モデルの評価には、BLEU(Bilingual Evaluation Understudy)スコアや人間の翻訳との比較などが使用されます。これらの評価基準により、NLLBモデルの翻訳品質や性能が客観的に評価されています。
NLLBモデルの開発プロセスにおいて、倫理的な配慮はどのように行われたか。
NLLBモデルの開発プロセスにおいて、倫理的な配慮が重要な役割を果たしています。Metaは、データ収集やモデルトレーニングの際に、プライバシーとデータセキュリティに配慮し、透明性を確保しています。また、NLLBプロジェクトチームは、文化的な尊重や言語の多様性を考慮しながら、モデルの開発を進めています。さらに、ユーザーのフィードバックを収集し、モデルの改善に取り組むことで、倫理的な配慮を実践しています。
NLLBモデルの活用により、言語の多様性を尊重し、社会的包摂を促進するためにはどのような取り組みが必要か。
言語の多様性を尊重し、社会的包摂を促進するためには、NLLBモデルの普及と利用を促進する取り組みが必要です。これには、教育機関や非営利団体との協力による普及活動、低所得国や地域における言語コミュニティとの連携、そしてユーザーのニーズに合わせたカスタマイズされた翻訳サービスの提供などが含まれます。さらに、NLLBモデルの継続的な改善と進化を通じて、より多くの言語をサポートし、社会的包摂を促進する取り組みが重要です。
0
Produkter | Ressurser
© 2024 by Linnk AI