
Generative AI Models Exhibit Catastrophic Collapse When Trained on Recursively Generated Data
The article discusses the potential issues that may arise when training large language models (LLMs) such as GPT-n on data that is increasingly generated by AI models themselves. It introduces the concept of 'model collapse', where the indiscriminate use of model-generated content in training leads to irreversible defects in the resulting models, causing the disappearance of tails of the original content distribution.
The authors build theoretical intuition behind this phenomenon and demonstrate its ubiquity across various generative models, including large language models, variational autoencoders (VAEs), and Gaussian mixture models (GMMs). They argue that this issue must be taken seriously to sustain the benefits of training from large-scale data scraped from the web, as the value of data collected about genuine human interactions with systems will become increasingly valuable in the presence of LLM-generated content.
The article highlights the need for careful curation and management of training data, as well as the development of techniques to mitigate the effects of model collapse, in order to ensure the continued success and reliability of generative AI systems.
Customize Summary
Rewrite with AI
Generate Citations
Translate Source
To Another Language
Generate MindMap
from source content
Visit Source
www.nature.com
AI models collapse when trained on recursively generated data - Nature
Kluczowe wnioski z
by Ilia Shumail... o www.nature.com 07-24-2024
https://www.nature.com/articles/s41586-024-07566-y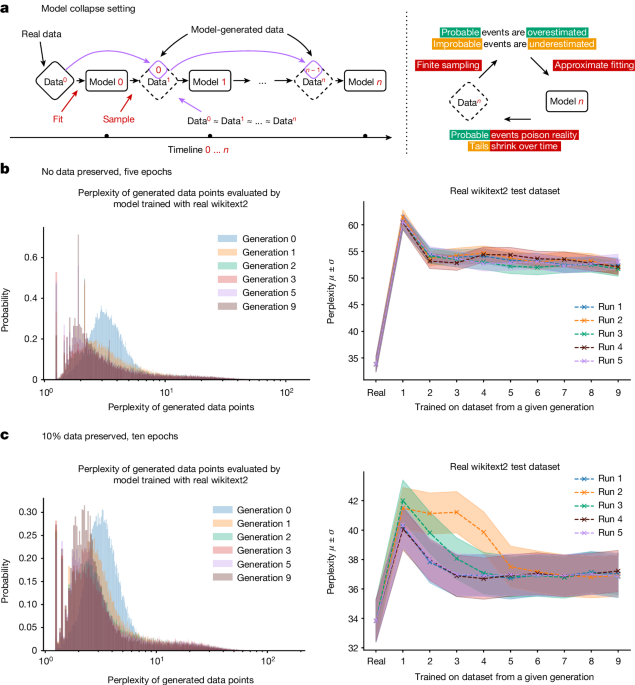
Głębsze pytania
How can we develop techniques to effectively detect and mitigate the effects of model collapse in generative AI systems?
What are the potential long-term implications of model collapse on the broader ecosystem of online text and images, and how can we address these challenges?
How might the insights from this research on model collapse inform the development of more robust and reliable generative AI models that can better handle the increasing prevalence of AI-generated content in training data?
© 2024 by Linnk AI