
登入
核心概念
LLM 기반 텍스트 생성 시스템의 허구 문제를 해결하기 위해 LLM 자체를 활용하는 방법을 제안한다.
摘要
이 논문은 LLM(Large Language Model)을 활용하여 LLM 자체의 허구 문제를 해결하는 방법을 제안한다. LLM은 자연스러운 대화 인터페이스를 통해 광범위한 지식에 쉽게 접근할 수 있어 과학자, 프로그래머, 경영진 등 다양한 분야에서 활용되고 있다. 그러나 LLM이 질문이나 프롬프트에 대해 사실적으로 잘못되거나 관련 없는 응답을 생성하는 '허구' 문제가 발생할 수 있다.
이 논문에서는 특정 유형의 허구인 '혼동'을 탐지하는 방법을 제안한다. 혼동은 LLM이 질문에 대해 겉보기에는 타당해 보이지만 실제로는 잘못된 답변을 생성하는 경우를 말한다. 이를 위해 LLM 자체를 활용하여 허구 탐지 모델을 개발하는 방식을 제안한다. 이를 통해 LLM의 장점을 활용하면서도 LLM의 한계를 극복할 수 있을 것으로 기대된다.
‘Fighting fire with fire’ — using LLMs to combat LLM hallucinations
統計資料
LLM이 정확한 답변 대신 허구를 생성하는 문제가 정기적으로 발생하며, 이는 오류와 피해로 이어질 수 있다.
引述
"LLM이 질문(또는 프롬프트)에 대해 겉보기에는 타당해 보이지만 실제로는 잘못된 답변을 생성하는 경우를 '혼동'이라고 한다."
"LLM 자체를 활용하여 허구 탐지 모델을 개발하는 방식을 제안한다."
從以下內容提煉的關鍵洞見
by Karin Verspo... 於 www.nature.com 06-19-2024
https://www.nature.com/articles/d41586-024-01641-0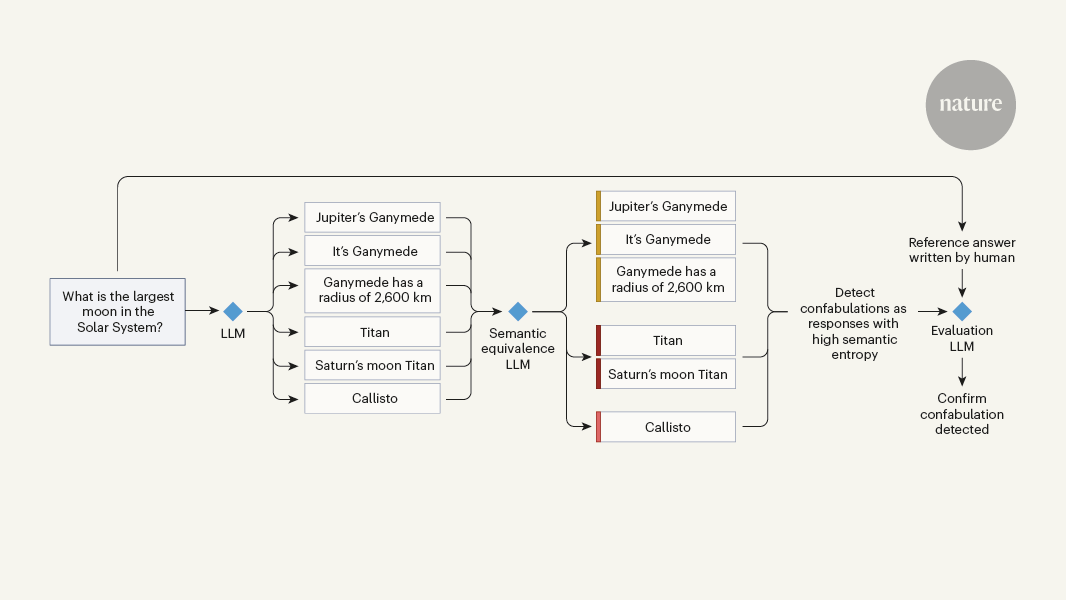
深入探究
LLM 기반 시스템의 허구 문제를 해결하기 위한 다른 접근법은 무엇이 있을까?
현재 LLM의 허구 문제를 해결하기 위한 다른 접근법 중 하나는 '불꽃으로 불을 끄기' 전략을 활용하는 것입니다. 이는 LLM이 생성한 허구적인 정보를 탐지하고 수정하는 방법으로, Farquhar 등이 개발한 특정 유형의 허구인 'confabulations'을 감지하는 방법이 이에 해당합니다. 또 다른 접근법은 LLM의 학습 데이터를 더욱 다양하고 정확하게 구성하여 모델의 일반화 능력을 향상시키는 것입니다. 이를 통해 모델이 현실적이고 정확한 정보를 생성하도록 유도할 수 있습니다.
LLM의 허구 문제가 특정 도메인이나 응용 분야에 더 심각하게 나타나는 이유는 무엇일까?
LLM의 허구 문제가 특정 도메인이나 응용 분야에 더 심각하게 나타나는 이유는 해당 분야의 전문적인 지식과 상황을 모델이 충분히 이해하지 못하기 때문입니다. 예를 들어, 의학 분야에서 LLM이 생성한 허구적인 정보는 환자의 건강에 직접적인 영향을 미칠 수 있습니다. 또한, 특정 도메인의 언어적 특성이나 전문 용어의 사용 등이 LLM의 허구 문제를 더욱 악화시킬 수 있습니다. 따라서, 특정 도메인에 대한 추가적인 지식을 모델에 통합하거나 해당 분야 전문가들의 지도를 받는 것이 이러한 문제를 완화하는 데 중요합니다.
LLM의 허구 문제를 해결하는 것 외에 LLM 기술의 어떤 다른 한계를 극복할 수 있을까?
LLM 기술의 다른 한계 중 하나는 데이터 편향성과 일반화 능력의 한계입니다. LLM은 대량의 데이터를 기반으로 학습되기 때문에 훈련 데이터에 존재하지 않는 패턴이나 정보에 대해 취약할 수 있습니다. 이를 극복하기 위해 데이터의 다양성을 확보하고 모델의 일반화 능력을 향상시키는 연구가 필요합니다. 또한, LLM의 해석가능성과 투명성 부족도 한계로 작용할 수 있습니다. 모델이 어떻게 결정을 내리는지 이해하기 어려울 수 있으며, 이는 신뢰성과 책임성 측면에서 문제가 될 수 있습니다. 이러한 한계를 극복하기 위해 해석 가능한 AI 기술의 개발과 모델의 의사 결정 과정을 설명할 수 있는 방법론의 연구가 중요합니다.
0