
Meta's RLEF Achieves State-of-the-Art Coding Performance by Fine-Tuning LLMs with Execution Feedback
Meta introduces a new fine-tuning method called Reinforcement Learning from Execution Feedback (RLEF) that significantly enhances the code-generating abilities of Large Language Models (LLMs). RLEF trains LLMs on traces of iterative code synthesis, enabling them to learn from execution feedback and refine their code generation process.
The researchers demonstrated RLEF's effectiveness by fine-tuning a Llama 3.1 8B model, achieving state-of-the-art performance on the challenging CodeContests benchmark. This fine-tuned model even outperformed GPT-4, the previous benchmark leader, despite being significantly smaller and operating in an iterative mode.
RLEF exhibits remarkable sample efficiency, achieving 40% accuracy (state-of-the-art) with only three code iterations. In contrast, other models fall short of this accuracy even with 100 iterations, highlighting RLEF's superior efficiency.
The success of RLEF stems from its ability to leverage execution feedback effectively, allowing the model to learn from its mistakes and improve its code generation iteratively. This approach enables the model to achieve higher accuracy with fewer iterations, making it a promising avenue for developing more efficient and capable code generation systems.
Tùy Chỉnh Tóm Tắt
Viết Lại Với AI
Tạo Trích Dẫn
Dịch Nguồn
Sang ngôn ngữ khác
Tạo sơ đồ tư duy
từ nội dung nguồn
Xem Nguồn
medium.com
Meta’s RLEF Turns Any LLM into a SOTA Coder
Thông tin chi tiết chính được chắt lọc từ
by Ignacio De G... lúc medium.com 10-14-2024
https://medium.com/@ignacio.de.gregorio.noblejas/metas-rlef-turns-any-llm-into-a-sota-coder-597f1aa37e20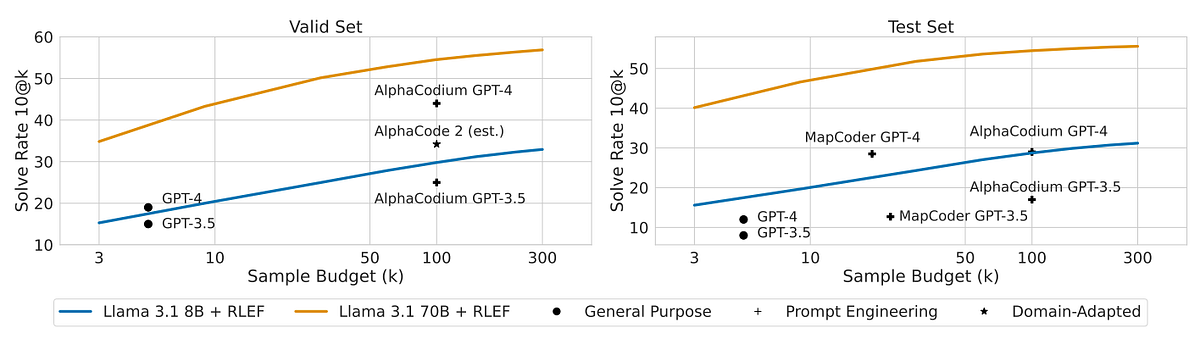
Yêu cầu sâu hơn
How does RLEF compare to other techniques that leverage feedback for code generation, such as those based on human feedback or program analysis?
Could the reliance on iterative code synthesis in RLEF potentially limit its applicability to tasks requiring real-time code generation or those with strict latency constraints?
If code generation becomes significantly more efficient and accessible, how might this impact the future of software development and the demand for human programmers?
© 2024 by Linnk AI